近日,永利魯劍鋒教授以6774澳门永利為第一單位,以第一作者/通訊作者在中國計算機學會(CCF)推薦的A類期刊IEEE Journal on Selected Areas in Communications和B類期刊ACM Transactions on Internet Technology,以及中國自動化學會(CAA)推薦的A類期刊IEEE Transactions on Industrial Informatics和IEEE Transactions on Computational Social Systems連續發表和錄用了六篇高水平期刊論文,有力推進了物聯網和人工智能交叉領域的前沿性研究工作,擴大了6774澳门永利計算機科學與技術學科在該領域的學術影響力。
論文1:Blockchain-Enabled Task Offloading with Energy Harvesting in Multi-UAV -assisted IoT Networks: A Multi-agent DRL Approach (IEEE Journal on Selected Areas in Communications)
無人機作為空中基站輔助物聯網是一項極具前景的技術,可解決諸如擴展網絡覆蓋、增強網絡性能、向物聯網設備傳輸能量、以及在物聯網設備上執行計算密集型任務等問題。由于異構的物聯網設備有限的處理能力,從而無法長時間執行資源密集型活動。此外,物聯網易受安全威脅和自然災害的影響,限制了其實時應用的執行。盡管已經有許多嘗試通過能量收集的計算卸載來解決資源短缺問題,截至目前,對緊急情況和脆弱性問題的研究仍然不足。因此,本文提出了一個基于區塊鍊和多智能體深度強化學習的集成框架,用于在多無人機輔助物聯網中使用能量收集進行計算卸載,其中物聯網設備從無人機獲取計算和能量源。首先,将優化問題表述為計算卸載和能量收集問題的聯合優化問題,同時考慮到最優資源價格。其次,将優化問題建模為Stackelberg博弈,通過允許物聯網設備和無人機不斷調整其資源需求和定價策略來研究它們之間的交互。特别地。所定義的形式化問題可以通過随機博弈模型間接解決,可最小化物聯網設備的計算成本,同時最大化無人機的效用。相應的,設計了一個基于多智能體深度強化學習的算法,采用了集中訓練和分散執行策略,利用算法自身動态性和高維特性,解決了所定義的問題,并通過廣泛的實驗結果進一步證明了所提出的框架的優越性。
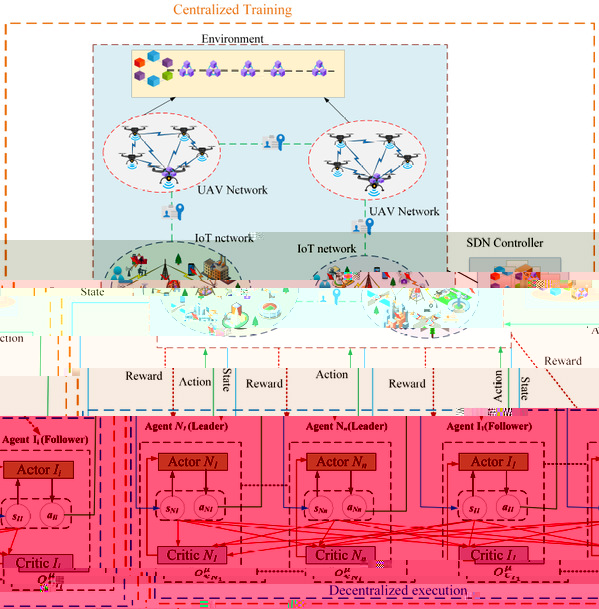
圖 SEQ 圖 \* ARABIC 1. 基于區塊鍊的多UAV輔助物聯網中的MADDPG框架
論文2:Towards Personalized Federated Learning via Group Collaboration in IIoT (IEEE Transactions on Industrial Informatics)
盡管聯邦學習已經在多個領域得到了快速發展,但是當與工業物聯網技術相結合時,依然面臨數據、模型以及邊緣設備的異構性挑戰。現有的研究工作主要關注于如何通過采用全局協作、聚類協作或成對協作模式實現的個性化模型的訓練。然而,全局協作模式無法解決在非獨立同分布數據的應用場景,聚類協作模式由于單一的聚類模式和高計算成本使得應用受限,成對協作模式的協作範圍較小并且通信成本高昂。針對以上問題,本文從多方博弈視角,提出了一種新穎的組協同個性化聯邦框架以解決現有協同模式存在的共性問題。首先,在個性化聯邦中将組協同模式建模成一個多領導者多追随者的Stackelberg博弈,利用博弈收益的勢函數特征,設計了ε-貪婪反應策略來計算其唯一的均衡解。考慮到博弈均衡的非最優性,設計了一個羅賓漢機制,利用轉移支付的思想來進一步提高訓練模型的性能,并給出了羅賓漢機制的可持續的和收斂性證明。最後,在模拟數據集和真實數據集上和現有協作模式的充分對比,驗證了所提出的組協作模式的高性能表現。
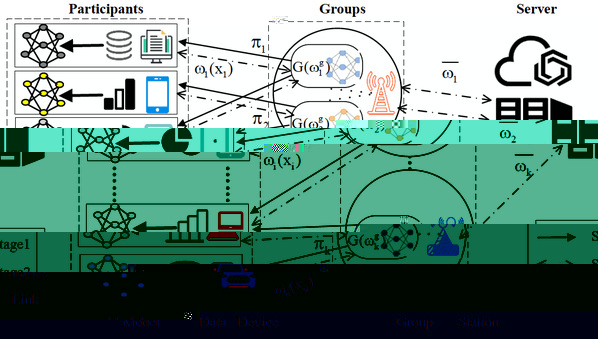
圖2. 個性化聯邦的組協同流程
論文3: Towards Fairness-Aware Time-Sensitive Asynchronous Federated Learning for Critical Energy Infrastructure (IEEE Transactions on Industrial Informatics)
關鍵能源基礎設施(CEI)系統對國民經濟和社會發展至關重要,但是當CEI與分布式機器學習技術相結合時容易受到網絡攻擊和數據隐私洩露等技術挑戰。盡管聯邦學習已成為一種新穎的符合隐私保護需求的分布式機器學習範式,但當複雜的聯邦任務應用于CEI時,組織邊緣計算節點之間的協作訓練是是一件非常困難的調度任務,特别是在未來信息不可預知的異步聯邦場景中,CEI系統必須立即做出不可撤銷的決定關于是否雇用動态到達和離開的邊緣計算節點。針對以上技術挑戰,本文設計了兼顧公平意識和時間敏感的任務分配的異步聯邦機制。首先,設計具有可靠性保障的多維契約機制,激勵參與者誠實公正,實現時間固定場景下的性能最優化。其次,設計了一個多尺度的參與者招募機制來最小化任務時間開銷,并給出了該問題的NP完全性證明,提出了一種基于松弛疊代優化的e-近似算法實現對時間成本的有效控制。大量真實數據和模拟數據的實驗論證進一步了表明了本文所提出的機制在分布式任務調度中在協同性能、公平性以及時間開銷上具有高性能表現。
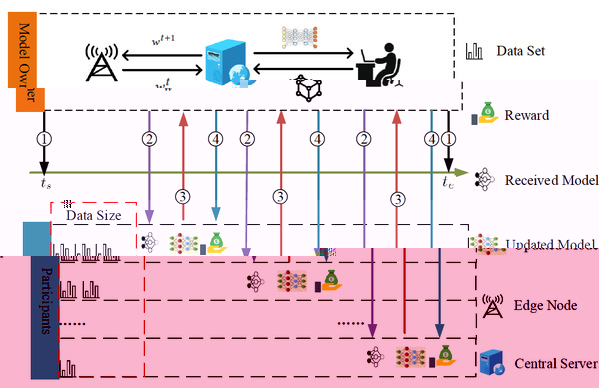
圖3. 異步聯邦學習的任務處理流程
論文4:A Green Stackelberg-Game Incentive Mechanism for Multi-Service Exchange in Mobile Crowdsensing (ACM Transactions on Internet Technology)
盡管移動群智感知已經成為一種收集、分析和利用大量感知數據的綠色範式,但現有的激勵機制并不能有效地激發用戶在多服務交換應用中的積極參與和高質貢獻,這是由于受制于其獨有特征:海量異構用戶具有不對稱的服務訴求、工作者可以自由選擇感知任務以及參與水平、并且異構型感知任務的不同價值屬于敏感信息可能不會被相應的請求者誠實聲明。為了解決以上問題,本文研發了一種綠色的Stackelberg博弈激勵機制,以在降低感知平台負擔的同時實現選擇性公平、真實性、以及有界效率保障。首先,将多服務交換問題建模為一個由多領導者多追随者組成的Stackelberg多服務交換博弈模型,其中作為領導者的請求者首先選擇獎勵申報策略,從而為每個感知任務支付相應費用。然後,作為追随者的工作人員選擇感知計劃策略,以最大化個體效用。接下來,我們引入虛拟貨币的概念,以保持用戶之間的選擇性公平性,并平衡服務請求和服務願景,其中用戶賺取/消費虛拟貨币以提供/接受服務,再次,我們提出了兩種新算法分别用于計算感知計劃決定博弈和獎勵聲明決定博弈的唯一納什均衡,這兩種算法的輸出共同組成了所提出博弈的唯一Stackelberg均衡。特别的,我們從理論上證明了所提出的機制具有三條理想性質。最後,與基線和理論優化方法相比,我們提供了廣泛的評估結果,以支持所設計機制的正确性和有效性。
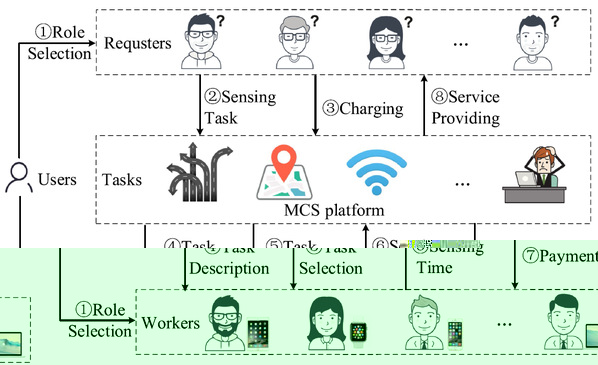
圖4. 綠色Stackelberg激勵機制在多服務交換移動群智感知系統中的交互流程
論文5: Extortion and Cooperation in Rating Protocol Design for Competitive Crowdsourcing (IEEE Transactions on Computational Social Systems)
衆包作為一種利用人類智慧和活動來解決廣泛任務的典範,通過向在線群體下的衆多用戶征求貢獻來獲得所需的數據或服務,提供了一種分布式、具有成本效益的方法。然而在監督不完善的情況下,衆包中具有競争利益的異質工人傾向于擊敗對手以獲得更大的自我利益,自由和頻繁的更換對手的競争特點使得實際博弈場景更為複雜。為了将以上特征納入讨論範疇,旨在加強合作同時剝削自私工作者,目的在于最大化請求者的效用,本文提出了一中增強合作與懲罰自私行為的激勵機制設計問題,将二元評級與差異定價相結合,開發了一種新的評級協議,在滿足可持續社會規範的充要條件下,設計了選擇最優設計參數的低複雜度算法,大量的評估結果證明了我們所設計的評級協議的性能,并揭示了内置參數對設計參數的影響。以上工作為解決競争性衆包下迫使自利的勞動者服從社會規範,克服社會不良均衡的低效問題,提供了理論與技術支撐。
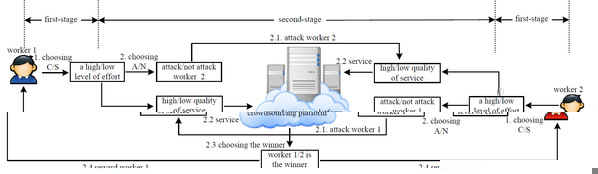
圖5. 一種典型的衆包競争困境博弈
論文6:Truthful Incentive Mechanism Design via Internalizing Externalities and LP Relaxation for Vertical Federated Learning (IEEE Transactions on Computational Social Systems)
縱向聯邦學習是一種多方聯合建模應用的分布式機器學習新範式。高效激勵有自我意識的客戶端積極可靠地參與縱向聯邦學習的協作可以提高模型訓練的能耗效率。我們為縱向聯邦學習開發了第一個真實的激勵機制,它可以處理信息自我披露和社會效用最大化問題。通過内部化外部性設計轉移支付規則,我們将客戶端的效用與社會效用關聯,使真實報告私人信息成為每個客戶的主導策略。我們證明了該機制可以實現真實性和社會效用最大化,并通過線性松弛進一步優化了樣本量決策規則,以滿足不同場景的需求。合成數據集和真實數據集上的實驗驗證了該機制的性能優于當前的流行方法。縱向聯邦學習的激勵機制可以促進不同類型機構之間的機器學習合作,更加有效地利用本地數據和計算資源。

圖6. 縱向聯邦學習激勵機制框架圖
魯劍鋒教授自2022年1月正式入職6774澳门永利,是湖北省“楚天學者”特聘教授、浙江省傑出青年基金獲得者、中國計算機學會物聯網/普适計算專委會執行委員、國家重點研發計劃“物聯網與智慧城市”重點專項答辯評審專家、湖北省/浙江省/廣東省科技計劃項目評審專家等。主要研究興趣包括聯邦學習、群智感知、博弈論及其應用等。近年來以第一作者/通訊作者在IEEE TIFS、IEEE JSAC、ACM TOIT、IEEE TII、IEEE TVT、IEEE TCSS、IEEE IOTJ、電子學報等國際著名學術期刊及會議上發表論文40餘篇。先後主持國家自然科學基金3項、省部級課題5項。指導研究生獲省/校優秀畢業生稱号、優秀碩士學位論文、研究生國家獎學金、校長特别獎多人次,多人畢業後赴上海交通大學等著名高校讀博深造。